It’s the Holy Grail for EMR implementations across multiple sites. How do you get true data mobility – the full patient record available to all users in all places – whilst supporting offline use with 100% functionality, from outreach teams to large tertiary hospitals?
This is why Tamanu is unique – it has universal sync.
If you’ve ever used Tamanu, you might have noticed that it looks fantastic, has great functionality, and is super intuitive to pick up (heh – well that’s what we think anyway!). But what our engineers are most proud of is something that you probably haven’t noticed at all – the sync engine. In this case, not being noticed is actually what we’re aiming for! Like a cricket umpire or football referee, a bad job will be really obvious, but good sync should fade into the background and “just work”, without the user having to think about it.
It’s not so easy to make that happen though. When we first built Tamanu, our prototype sync engine was honestly pretty unreliable. Users noticed it all the time, in a bad way. It ran too slowly and would sometimes silently fail – we never lost data and the system stayed up for users but data was not moving around as smoothly or quickly as we’d hoped. So, over the last two years, we’ve dedicated almost a quarter of our engineering time to focus solely on sync. Fortunately, as well as being challenging, it’s also really interesting and a source of endless fascination for our engineers at BES. The result of this work is a super-robust, super-fast sync engine for Tamanu, which we released in v2.0 at the start of 2024.
Why put in so much effort? Because a strong, stable sync engine is foundational to working offline. The ability to work offline is absolutely critical in the places Tamanu is used, and so is the ability for health workers to access up-to-date patient records, wherever that patient presents. This is not just about supporting outreach teams looking at individual patients – hospitals and health centres need a system where all users across a large facility can be accessing the same record, looking at the same version of the data, even when the facility goes offline (whether that is for minutes or for weeks). Back in 2018, when we looked around for a software that would achieve this, we came up short. No existing open-source EMR could work at a national scale, while allowing users to use the full set of functionality, offline, for as long as the internet might be down.
To this day, that’s still true. While other open-source options have some offline capabilities, they’re generally limited to specific workflows, and often just go in one direction.
For example, something that’s easy to do offline is submitting forms. You can download the form to the user’s device, and then cache their answer until the internet is available. This is the way Tupaia DataTrak works, and there’s nothing wrong with it at all for that use case! However, it doesn’t get you to the point that health workers can see all of a patient’s medical history, and continue to interact with that history without the internet.
For true offline capabilities, you need what we call “Universal Sync”. Universal because it covers 100% of functionality, across all locations and devices, for any amount of time. That means that information can travel in all directions across the health system, and be kept coherent and up-to-date, while also dealing with extended periods of internet downtime. The table below shows the differences between the basic sync systems that are most common, and Tamanu’s Universal Sync model.

Basic vs. Universal Sync: Side by side, the differences are stark

Case Studies
But hang on… the software we’re using says that it works ‘offline’? What’s the difference? It turns out there’s a lot of difference and ‘offline use’ can refer to a spectrum of functionality ranging from submitting a single form response on a mobile device, all the way up to hundreds of simultaneous desktop users with a fully functional EMR in a tertiary hospital.
Case Study 1: Tupaia DataTrak
DataTrak is designed to collect data at health facilities and other locations via offline forms. It implements a form of Basic Sync, downloading all surveys and questions ahead of time so they can be filled out without an internet connection. It caches them using very modern technology, with a full database embedded in the database, able to run fast and store large amounts of data by combining WASM and OPFS (don’t worry if you haven’t heard of them!).
When the internet is available, Tupaia DataTrak will sync all answers back up to a central server. It is limited by all the constraints of Basic Sync listed above, though with a very high maximum db size and length of time offline. Those constraints are completely acceptable when the use case is focused solely on collecting survey data, as opposed to providing full health system functionality.
Case Study 2: KoboToolbox WebForms
KoboToolbox uses Enketo WebForms to provide Basic Sync in a very similar way to Tupaia DataTrak, just with older technology used to cache data in the browser. As such it is limited by the same set of Basic Sync constraints, but additionally has lower limits on the amount of data and length of offline support. Again, this is generally not an issue in real world scenarios, as it is specifically designed for collecting information through surveys and forms rather than managing patient data or health system workflows.
Case Study 3: KoboCollect
KoboCollect uses SQLite natively in an Android app, so extends upon the WebForms option in terms of the scale and longevity of data it can cache. However, it is only available on Android devices, and also requires more user intervention to send data to the central server, rather than automatically syncing in the background.
As with the previous two case studies, the limitations of Basic Sync are not hugely detrimental in the context of collecting data that is generally aggregate, and only used for reporting rather than operational or clinical workflows.
Case Study 4: Bahmni Connect
Bahmni Connect is a heavily stripped back version of the Bahmni port of OpenMRS. It provides offline support for a few basic workflows, including viewing a subset of patient data, registration of new patients, and recording observations against patients.
The web app stores data offline using a browser cache, but because it was built before most databases supported browser builds via WASM, this cache is limited in performance and scale. Bahmni provides an estimated maximum of 2GB, and while that is smaller than a large facility might require, it is plenty for the limited data types and workflows supported.
In terms of longevity of data, the browser technology used comes with a disclaimer that data may be purged at any time, losing it from offline access. However, this right-to-purge is seldom enacted by browsers, so it is unlikely to be an issue in most cases.
While Bahmni Connect has much more of a clinical focus than the previous three case studies, it is only designed for use in outreach settings, as the per-device cache and limited workflow support would not be ideal in a medium to large health facility.
It is worth noting that Bahmni Connect is now marked as deprecated in some documentation, though it is likely still to be in use for some time as projects migrate to other options.
Case Study 5: Bahmni Outreach App for Community Health
The Bahmni Outreach App is built to support community health workers (CHWs) in offline environments. It allows health workers to register patients, record basic observations, and track health programs like immunizations or antenatal care. It uses more modern technology than earlier Bahmni solutions, leveraging the third-party open source project Avni.
Avni stores data locally on a mobile device, using a database called Realm. To limit the database size growing too large, each device will only store predefined subsets of patient data based on catchment area. This is helpful in allowing the app to operate at scale, but may create difficulties when interacting with patients from outside of the predefined list.
The app does support bidirectional sync of some data types, allowing registration and editing of basic patient details, as well as recording vitals, entering lab results, and making referrals. This data will sync to Avni when the app is online and open, and from there an integration service transmits it back into Bahmni.
Outsourcing the sync engine to a pre-existing project brings some benefits for Bahmni, including being able to launch a new offline app quickly. There are also some downsides, including the overhead of installing an additional server, app, and integration engine, as well as the need to keep metadata updated in concert across both systems. Because Avni was not designed for clinical workflows, all concepts in Bahmni need to be mapped to entities and form fields that are otherwise used for reporting-oriented data collection. Some of this is done automatically, and Bahmni have also written an upgrade guide detailing how to set up the initial mapping.
The Bahmni Outreach App for Community Health is designed for small-scale, community-based health initiatives, and the limitations of Basic Sync are likely to be acceptable in these contexts. However, because it is only available on Android mobile devices, and the workflows are limited, it is unlikely to be useful for larger clinical settings.
Case Study 6: OpenMRS Offline Community Outreach
While it is no longer maintained, a notable mention is OpenMRS 3 Offline Community Outreach, which introduced the ability to interact with some features of OpenMRS offline. Like the Bahmni offline offerings, the system is focused on community health workers, so only supports basic patient details, and submitting forms.
One downside of the OpenMRS system compared to Bahmni is that it requires a lot of hands-on interaction from users. They need to make sure to manually add patients to the offline list before they go offline. Sync is also quite manual, requiring the user to click the download button to get the latest data, and staying on that page while the data syncs. This works really well for community outreach, where you might know the set of patients who you are visiting that day, and can download them in advance. However, it is more risky when dealing with unexpected internet outages, as patient data may or may not be available.
Both the manual steps required, and the range of functionality that is available, are areas of active work for OpenMRS, so we can expect to see some improvements in future.
As with Bahmni Connect and Tupaia DataTrak, because the offline cache is based on browser technologies, the size is limited and potentially subject to purge or accidental deletion if the user clears the cache. This decision is another one that is really focused on their core use case of community health workers. In a hospital, as well as the larger data size, the browser based data storage mechanisms don’t generally work as it requires every individual user to independently sync, constantly.
Case Study 7: EMR4All (OpenMRS 3 on Raspberry Pi)

The EMR4All project aims to have OpenMRS 3 run on a local Raspberry Pi, and synchronise with a cloud server. This is a really fantastic step, and if successful, will bring OpenMRS closer to that Universal Sync holy grail, at least for smaller facilities. The project is still in the proof of concept phase, with sync set up just for a set of 5 core tables, as of October 2024. There is also still some friction in the sync system, for example needing to manually rebuild search indexes after each sync.
If taken to production at scale, the syncing Raspberry Pi approach will be analogous to the Tamanu Iti mini-servers that BES provides. In fact, they contain pretty much the exact same set of components, with the only major difference that the Tamanu Iti includes an inbuilt battery to handle temporary power outages without any peripherals. With several of these Iti’s hosting Tamanu in production across the Pacific, we can attest to it being a successful model in situations where internet and power connectivity is an issue.
The first target of the synchronising Raspberry Pi will naturally be smaller, more remote facilities with correspondingly lower data throughput. Of course, larger hospitals require significantly more data to flow through the system, but if OpenMRS is able to build upon the same sync engine to handle the breadth and volume of data required, it’s possible that the EMR4All project could be the first building block for those contexts as well. Polishing and battle-testing the system will likely take some time, as will adding support for all tables needed in full-service facilities, but it is well worth keeping an eye on progress over the coming years.
Case Study 8: Tamanu
As you’re aware by now, Tamanu implements Universal Sync, meaning all functionality and all data is available offline, in every situation you might want to use Tamanu.
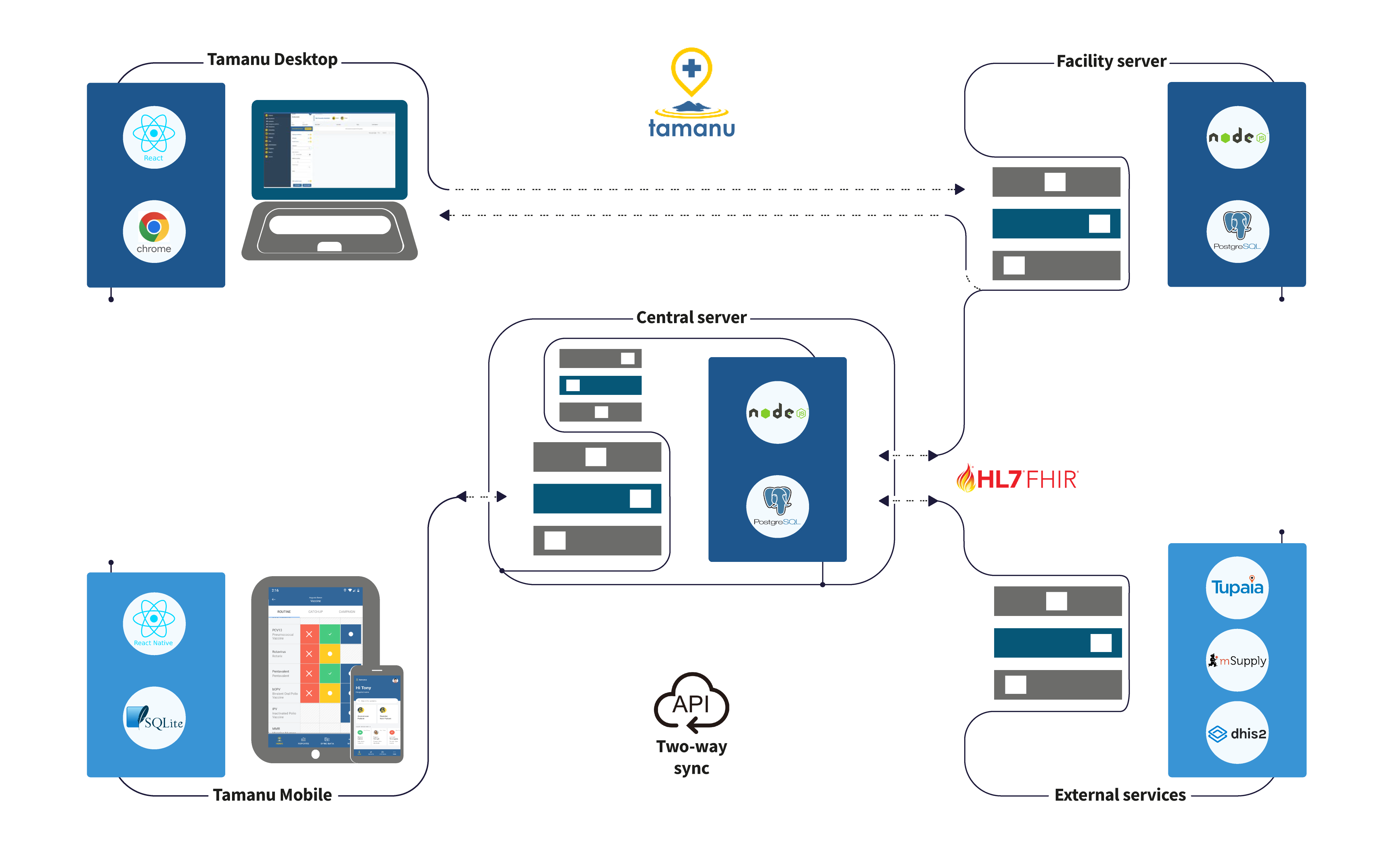
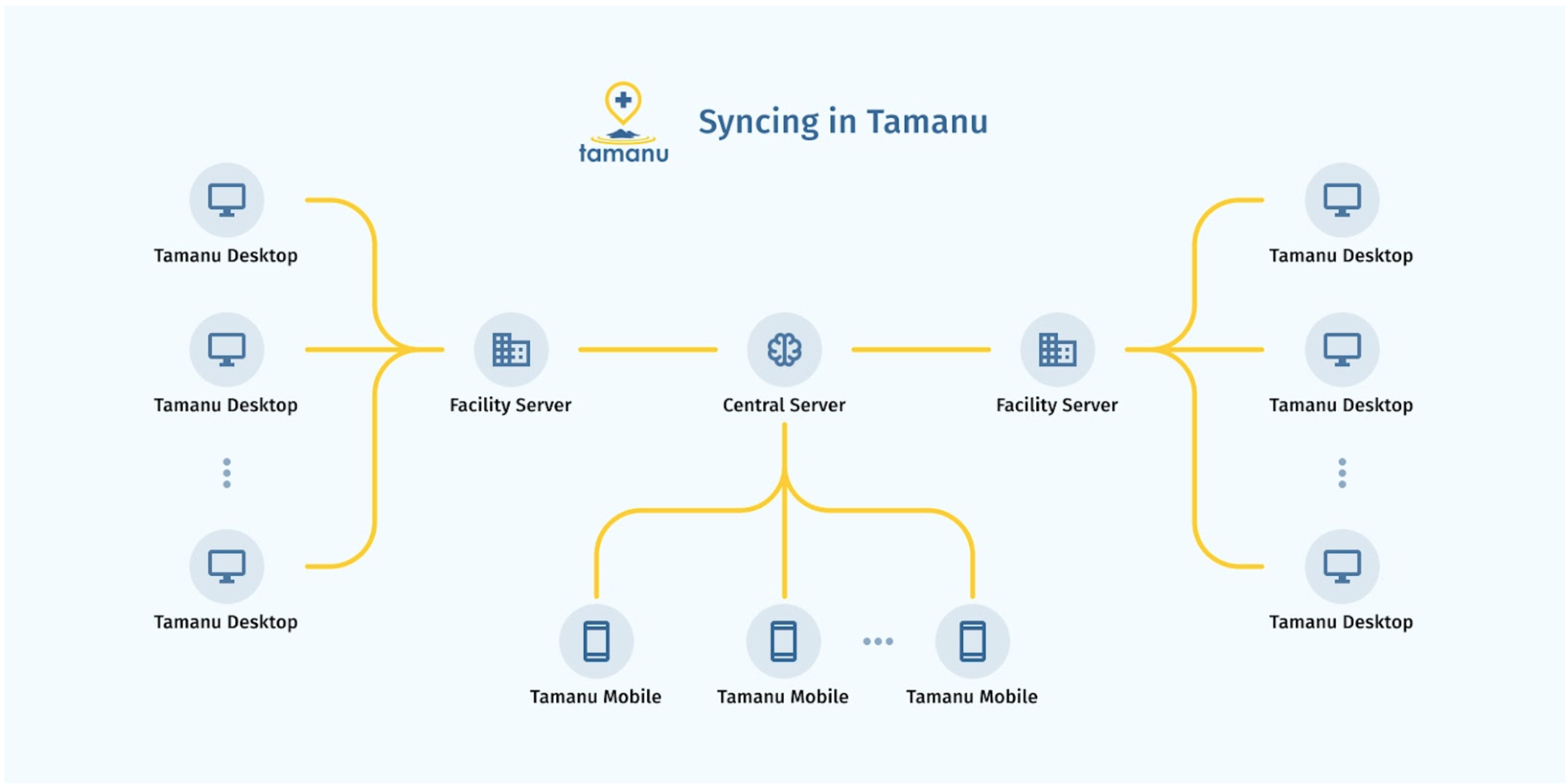
Tamanu Desktop achieves this using a distributed server architecture, where each facility has a local server with full enterprise-grade support for all operational and clinical workflows. This local server stores all required data for that facility, and automatically syncs with other facilities every minute. Tamanu servers use PostgreSQL as the back end database, which is proven to work at the huge scale of systems like Netflix. The huge benefit of using a per-facility local server, rather than a per-device cache, is that all users in the facility are using a common source of data. This means that if a nurse takes vitals for a patient, the results are visible for all other users instantaneously, without the lag of a sync cycle.
Tamanu also has a mobile application, which uses an SQLite database to store full records for any patient that has previously been seen in that facility. Tamanu Mobile also syncs automatically, on a 5 minute schedule. Currently Tamanu Mobile is only available on Android, like other mobile apps covered earlier.
Just like the Tamanu Desktop application, the Tamanu Mobile can be used offline for any amount of time. Unlike the desktop application, it does not require connection to a local network. This makes it great for outreach into rural communities, or running small facilities with little to no network connectivity.
All facility servers and mobile devices sync via a central server. The central server manages conflict resolution of concurrent edits via record- and field-wise comparisons of when the last update happened. Updates are tracked on a globally coherent timeline using a “logical clock”, which gets around issues with inconsistencies across clock time on each device. This architecture allows bidirectional sync, so that any record (patient) in the system can be edited on all devices by any user at any time without fear of conflicts.
Bonus benefits of Universal Sync
Other than offline access, there are some other benefits of a universal sync system. One is disaster recovery – in the technical sense of a server failing, but often caused by a real-world disaster! For example, in a cyclone, a server room may become flooded. Because all patient interactions are already synced to the central server, the IT team can set up a “failover” server that syncs that information down, and is quickly available to work from.
The same attribute of real-time data replication also prevents a very real security vulnerability. Hospitals around the world have had their server taken over by hackers, who will stop people using it until a ransom is paid. With a live backup of data on multiple servers across the distributed system, it becomes nearly impossible for them to take hold of everything. The Universal Sync model allows failover servers that can be started and synced, removing any disruption or need to negotiate with bad actors.
Finally, having data synced down means that things work really fast. When a user pulls up a patient’s medical history, Tamanu doesn’t have to fetch that over the internet, the data is right there on the local database.